Кодирование текстовой информации. Бинарные коды Декодирование бинарного кода
Бинарный код представляет собой текст, инструкции процессора компьютера или другие данные с использованием любой двухсимвольной системы. Чаще всего это система 0 и 1. назначает шаблон бинарных цифр (бит) каждому символу и инструкции. Например, бинарная строка из восьми бит может представлять любое из 256 возможных значений и поэтому может генерировать множество различных элементов. Отзывы о бинарном коде мирового профессионального сообщества программистов свидетельствуют о том, что это основа профессии и главный закон функционирования вычислительных систем и электронных устройств.
Расшифровка бинарного кода
В вычислениях и телекоммуникациях бинарные коды используются для различных методов кодирования символов данных в битовые строки. Эти методы могут использовать строки фиксированной или переменной ширины. Для перевода в бинарный код существует множество наборов символов и кодировок. В коде с фиксированной шириной каждая буква, цифра или другой символ представляется битовой строкой той же длины. Эта битовая строка, интерпретируемая как бинарное число, обычно отображается в кодовых таблицах в восьмеричной, десятичной или шестнадцатеричной нотации.
Расшифровка бинарного кода: битовая строка, интерпретируемая как бинарное число, может быть переведена в десятичное число. Например, нижний регистр буквы a, если он представлен битовой строкой 01100001 (как и в стандартном коде ASCII), также может быть представлен как десятичное число 97. Перевод бинарного кода в текст представляет собой ту же процедуру, только в обратном порядке.

Как это работает
Из чего состоит бинарный код? Код, используемый в цифровых компьютерах, основан на в которой есть только два возможных состояния: вкл. и выкл., обычно обозначаемые нулем и единицей. Если в десятичной системе, которая использует 10 цифр, каждая позиция кратна 10 (100, 1000 и т. д.), то в двоичной системе каждое цифровое положение кратно 2 (4, 8, 16 и т. д.). Сигнал двоичного кода представляет собой серию электрических импульсов, которые представляют числа, символы и операции, которые необходимо выполнить.
Устройство, называемое часами, посылает регулярные импульсы, а такие компоненты, как транзисторы, включаются (1) или выключаются (0), чтобы передавать или блокировать импульсы. В двоичном коде каждое десятичное число (0-9) представлено набором из четырех двоичных цифр или битов. Четыре основных арифметических операции (сложение, вычитание, умножение и деление) могут быть сведены к комбинациям фундаментальных булевых алгебраических операций над двоичными числами.
Бит в теории связи и информации представляет собой единицу данных, эквивалентную результату выбора между двумя возможными альтернативами в системе двоичных номеров, обычно используемой в цифровых компьютерах.

Отзывы о бинарном коде
Характер кода и данных является базовой частью фундаментального мира ИТ. C этим инструментом работают специалисты мирового ИТ-«закулисья» — программисты, чья специализация скрыта от внимания рядового пользователя. Отзывы о бинарном коде от разработчиков свидетельствуют о том, что эта область требует глубокого изучения математических основ и большой практики в сфере матанализа и программирования.
Бинарный код — это простейшая форма компьютерного кода или данных программирования. Он полностью представлен двоичной системой цифр. Согласно отзывам о бинарном коде, его часто ассоциируется с машинным кодом, так как двоичные наборы могут быть объединены для формирования исходного кода, который интерпретируется компьютером или другим аппаратным обеспечением. Отчасти это верно. использует наборы двоичных цифр для формирования инструкций.
Наряду с самой базовой формой кода двоичный файл также представляет собой наименьший объем данных, который протекает через все сложные комплексные аппаратные и программные системы, обрабатывающие сегодняшние ресурсы и активы данных. Наименьший объем данных называется битом. Текущие строки битов становятся кодом или данными, которые интерпретируются компьютером.

Двоичное число
В математике и цифровой электронике двоичное число — это число, выраженное в системе счисления base-2 или двоичной цифровой системе, которая использует только два символа: 0 (ноль) и 1 (один).
Система чисел base-2 представляет собой позиционную нотацию с радиусом 2. Каждая цифра упоминается как бит. Благодаря своей простой реализации в цифровых электронных схемах с использованием логических правил, двоичная система используется почти всеми современными компьютерами и электронными устройствами.
История
Современная бинарная система чисел как основа для двоичного кода была изобретена Готтфридом Лейбницем в 1679 году и представлена в его статье «Объяснение бинарной арифметики». Бинарные цифры были центральными для теологии Лейбница. Он считал, что двоичные числа символизируют христианскую идею творчества ex nihilo, или творение из ничего. Лейбниц пытался найти систему, которая преобразует вербальные высказывания логики в чисто математические данные.
Бинарные системы, предшествующие Лейбницу, также существовали в древнем мире. Примером может служить китайская бинарная система И Цзин, где текст для предсказания основан на двойственности инь и ян. В Азии и в Африке использовались щелевые барабаны с бинарными тонами для кодирования сообщений. Индийский ученый Пингала (около 5-го века до н.э.) разработал бинарную систему для описания просодии в своем произведении «Чандашутрема».
Жители острова Мангарева во Французской Полинезии использовали гибридную бинарно-десятичную систему до 1450 года. В XI веке ученый и философ Шао Юн разработал метод организации гексаграмм, который соответствует последовательности от 0 до 63, как представлено в бинарном формате, причем инь равен 0, янь — 1. Порядок также является лексикографическим порядком в блоках элементов, выбранных из двухэлементного набора.

Новое время
В 1605 году обсудил систему, в которой буквы алфавита могут быть сведены к последовательностям бинарных цифр, которые затем могут быть закодированы как едва заметные вариации шрифта в любом случайном тексте. Важно отметить, что именно Фрэнсис Бэкон дополнил общую теории бинарного кодирования наблюдением, что этот метод может использован с любыми объектами.
Другой математик и философ по имени Джордж Бул опубликовал в 1847 году статью под названием «Математический анализ логики», в которой описывается алгебраическая система логики, известная сегодня как булева алгебра. Система была основана на бинарном подходе, который состоял из трех основных операций: AND, OR и NOT. Эта система не была введена в эксплуатацию, пока аспирант из Массачусетского технологического института по имени Клод Шеннон не заметил, что булева алгебра, которую он изучил, была похожа на электрическую цепь.
Шеннон написал диссертацию в 1937 году, в которой были сделаны важные выводы. Тезис Шеннона стал отправной точкой для использования бинарного кода в практических приложениях, таких как компьютеры и электрические схемы.

Другие формы двоичного кода
Битовая строка не является единственным типом двоичного кода. Двоичная система в целом — это любая система, которая допускает только два варианта, таких как переключатель в электронной системе или простой истинный или ложный тест.
Брайль — это тип двоичного кода, который широко используется слепыми людьми для чтения и записи на ощупь, названный по имени его создателя Луи Брайля. Эта система состоит из сеток по шесть точек в каждой, по три на столбец, в котором каждая точка имеет два состояния: приподнятые или углубленные. Различные комбинации точек способны представлять все буквы, цифры и знаки пунктуации.
Американский стандартный код для обмена информацией (ASCII) использует 7-битный двоичный код для представления текста и других символов в компьютерах, оборудовании связи и других устройствах. Каждой букве или символу присваивается номер от 0 до 127.
Двоично-кодированное десятичное значение или BCD — это двоичное кодированное представление целочисленных значений, которое использует 4-битный граф для кодирования десятичных цифр. Четыре двоичных бита могут кодировать до 16 различных значений.
В номерах с кодировкой BCD только первые десять значений в каждом полубайте являются корректными и кодируют десятичные цифры с нулем, через девять. Остальные шесть значений являются некорректными и могут вызвать либо машинное исключение, либо неуказанное поведение, в зависимости от компьютерной реализации арифметики BCD.

Арифметика BCD иногда предпочтительнее числовых форматов с плавающей запятой в коммерческих и финансовых приложениях, где сложное поведение округления чисел является нежелательным.
Применение
Большинство современных компьютеров используют программу бинарного кода для инструкций и данных. Компакт-диски, DVD-диски и диски Blu-ray представляют звук и видео в двоичной форме. Телефонные звонки переносятся в цифровом виде в сетях междугородной и мобильной телефонной связи с использованием импульсно-кодовой модуляции и в сетях передачи голоса по IP.
Двоичный код - это подача информации путем сочетания символов 0 или 1. Порою бывает очень сложно понять принцип кодирования информации в виде этих двух чисел, однако мы постараемся все подробно разъяснить.
Кстати, на нашем сайте вы можете перевести любой текст в десятичный, шестнадцатеричный, двоичный код воспользовавшись Калькулятором кодов онлайн .
Видя что-то впервые, мы зачастую задаемся логичным вопросом о том, как это работает. Любая новая информация воспринимается нами, как что-то сложное или созданное исключительно для разглядываний издали, однако для людей, желающих узнать подробнее о двоичном коде , открывается незамысловатая истина - бинарный код вовсе не сложный для понимания, как нам кажется. К примеру, английская буква T в двоичной системе приобретет такой вид - 01010100, E - 01000101 и буква X - 01011000. Исходя из этого, понимаем, что английское слово TEXT в виде двоичного кода будет выглядеть таким вот образом: 01010100 01000101 01011000 01010100. Компьютер понимает именно такое изложение символов для данного слова, ну а мы предпочитаем видеть его в изложении букв алфавита.
На сегодняшний день двоичный код активно используется в программировании, поскольку работают вычислительные машины именно благодаря ему. Но программирование не свелось до бесконечного набора нулей и единиц. Поскольку это достаточно трудоемкий процесс, были приняты меры для упрощения понимания между компьютером и человеком. Решением проблемы послужило создание языков программирования (бейсик, си++ и т.п.). В итоге программист пишет программу на языке, который он понимает, а потом программа-компилятор переводит все в машинный код, запуская работу компьютера.
Перевод натурального числа десятичной системы счисления в двоичную систему.
Чтобы перевести числа из десятичной системы счисления в двоичную пользуются "алгоритмом замещения", состоящим из такой последовательности действий:
1. Выбираем нужное число и делим его на 2. Если результат деления получился с остатком, то число двоичного кода будет 1, если остатка нет - 0.
2. Откидывая остаток, если он есть, снова делим число, полученное в результате первого деления, на 2. Устанавливаем число двоичной системы в зависимости от наличия остатка.
3. Продолжаем делить, вычисляя число двоичной системы из остатка, до тех пор, пока не дойдем до числа, которое делить нельзя - 0.
4. В этот момент считается, что двоичный код готов.
Для примера переведем в двоичную систему число 7:
1. 7: 2 = 3.5. Поскольку остаток есть, записываем первым числом двоичного кода 1.
2. 3: 2 = 1.5. Повторяем процедуру с выбором числа кода между 1 и 0 в зависимости от остатка.
3. 1: 2 = 0.5. Снова выбираем 1 по тому же принципу.
4. В результате получаем, переведенный из десятичной системы счисления в двоичную, код - 111.
Таким образом можно переводить бесконечное множество чисел. Теперь попробуем сделать наоборот - перевести число из двоичной в десятичную.
Перевод числа двоичной системы в десятичную.
Для этого нам нужно пронумеровать наше двоичное число 111 с конца, начиная нулем. Для 111 это 1^2 1^1 1^0. Исходя из этого, номер для числа послужит его степенем. Далее выполняем действия по формуле: (x * 2^y) + (x * 2^y) + (x * 2^y), где x - порядковое число двоичного кода, а y - степень этого числа. Подставляем наше двоичное число под эту формулу и считаем результат. Получаем: (1 * 2^2) + (1 * 2^1) + (1 * 2^0) = 4 + 2 + 1 = 7.
Немного из истории двоичной системы счисления.
Принято считать, что впервые двоичную систему предложил Готфрид Вильгельм Лейбниц, который считал систему полезной в сложных математических вычислениях и науке. Но по неким данным, до его предложения о двоичной системе счисления, в Китае появилась настенная надпись, которая расшифровывалась при использовании двоичного кода . На надписи были изображены длинные и короткие палочки. Предполагая, что длинная это 1, а короткая палочка - 0, есть доля вероятности, что в Китае идея двоичного кода существовала многим ранее его официального открытия. Расшифровка кода определила там только простое натуральное число, однако это факт, который им и остается.
На данном уроке будет рассмотрена тема «Кодирование информации. Двоичное кодирование. Единицы измерения информации». В ходе него пользователи смогут получить представление о кодировании информации, способах восприятия информации компьютеров, единицах ее измерения и двоичном кодировании.
Тема: Информация вокруг нас
Урок: Кодирование информации. Двоичное кодирование. Единицы измерения информации
На данном уроке будут рассмотрены следующие вопросы:
1. Кодирование как изменение формы представления информации.
2. Как компьютер распознает информацию?
3. Как измерить информацию?
4. Единицы измерения информации.
В мире кодов
Зачем люди кодируют информацию?
1. Скрыть ее от других (зеркальная тайнопись Леонардо да Винчи, военные шифровки).
2. Записать информацию короче (стенография, аббревиатура, дорожные знаки).
3. Для более легкой обработки и передачи (азбука Морзе, перевод в электрические сигналы - машинные коды).
Кодирование - это представление информации с помощью некоторого кода.
Код - это система условных знаков для представления информации.
Способы кодирования информации
1. Графический (см. Рис. 1) (с помощью рисунков и знаков).
Рис. 1. Система сигнальных флагов (Источник)
2. Числовой (с помощью чисел).
Например: 11001111 11100101.
3. Символьный (с помощью символов алфавита).
Например: НКМБМ ЧГЁУ.
Декодирование - это действие по восстановлению первоначальной формы представления информации. Для декодирования необходимо знать код и правила кодирования.
Средством кодирования и декодирования служит кодовая таблица соответствия. Например, соответствие в различных системах счисления - 24 - XXIV, соответствие алфавита каким-либо символам (Рис. 2).

Рис. 2. Пример шифра (Источник)
Примеры кодирования информации
Примером кодирования информации является азбука Морзе (см. Рис. 3).

Рис. 3. Азбука Морзе ()
В азбуке Морзе используется всего 2 символа - точка и тире (короткий и длинный звук).
Еще одним примером кодирования информации является флажковая азбука (см. Рис. 4).

Рис. 4. Флажковая азбука ()
Также примером является азбука флагов (см. Рис. 5).

Рис. 5. Азбука флагов ()
Всем известный пример кодирования - нотная азбука (см. Рис. 6).

Рис. 6. Нотная азбука ()
Рассмотрим следующую задачу:
Используя таблицу флажковой азбуки (см. Рис. 7), необходимо решить следующую задачу:

Рис. 7
Старший помощник Лом сдает экзамен капитану Врунгелю. Помогите ему прочитать следующий текст (см. Рис. 8):

Вокруг нас существуют преимущественно два сигнала, например:
Светофор: красный - зеленый;
Вопрос: да - нет;
Лампа: горит - не горит;
Можно - нельзя;
Хорошо - плохо;
Истина - ложь;
Вперед - назад;
Есть - нет;
Всё это сигналы, обозначающие количество информации в 1 бит.
1 бит - это такое количество информации, которое позволяет нам выбрать один вариант из двух возможных.
Компьютер - это электрическая машина, работающая на электронных схемах. Чтобы компьютер распознал и понял вводимую информацию, ее надо перевести на компьютерный (машинный) язык.
Алгоритм, предназначенный для исполнителя, должен быть записан, то есть закодирован, на языке, понятном компьютеру.
Это электрические сигналы: проходит ток или не проходит ток.
Машинный двоичный язык - последовательность "0" и "1". Каждое двоичное число может принимать значение 0 или 1.
Каждая цифра машинного двоичного кода несет количество информации, равное 1 бит.
Двоичное число, которое представляет наименьшую единицу информации, называется б ит . Бит может принимать значение либо 0, либо 1. Наличие магнитного или электронного сигнала в компьютере означает 1, отсутствие 0.
Строка из 8 битов называется б айт . Эту строку компьютер обрабатывает как отдельный символ (число, букву).
Рассмотрим пример. Слово ALICE состоит из 5 букв, каждая из которых на языке компьютера представлена одним байтом (см. Рис. 10). Стало быть, Alice можно измерить как 5 байт.

Рис. 10. Двоичный код (Источник)
Кроме бита и байта, существуют и другие единицы измерения информации.
Список литературы
1. Босова Л.Л. Информатика и ИКТ: Учебник для 5 класса. - М.: БИНОМ. Лаборатория знаний, 2012.
2. Босова Л.Л. Информатика: Рабочая тетрадь для 5 класса. - М.: БИНОМ. Лаборатория знаний, 2010.
3. Босова Л.Л., Босова А.Ю. Уроки информатики в 5-6 классах: Методическое пособие. - М.: БИНОМ. Лаборатория знаний, 2010.
2. Фестиваль "Открытый урок" ().
Домашнее задание
1. §1.6, 1.7 (Босова Л.Л. Информатика и ИКТ: Учебник для 5 класса).
2. Стр. 28, задания 1, 4; стр. 30, задания 1, 4, 5, 6 (Босова Л.Л. Информатика и ИКТ: Учебник для 5 класса).
Множество символов, с помощью которых записывается текст, называется алфавитом .
Число символов в алфавите – это его мощность .
Формула определения количества информации: N = 2 b ,
где N – мощность алфавита (количество символов),
b – количество бит (информационный вес символа).
В алфавит мощностью 256 символов можно поместить практически все необходимые символы. Такой алфавит называется достаточным.
Т.к. 256 = 2 8 , то вес 1 символа – 8 бит.
Единице измерения 8 бит присвоили название 1 байт:
1 байт = 8 бит.
Двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
Каким же образом текстовая информация представлена в памяти компьютера?
Удобство побайтового кодирования символов очевидно, поскольку байт - наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу.
Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
Международным стандартом для ПК стала таблица ASCII (читается аски) (Американский стандартный код для информационного обмена).
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
Порядковый номер |
Код |
Символ |
0 - 31 |
00000000 - 00011111 |
Символы с номерами от 0 до 31 принято называть управляющими. |
32 - 127 |
00100000 - 01111111 |
Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы. |
128 - 255 |
10000000 - 11111111 |
Альтернативная часть таблицы (русская).
|
Первая половина таблицы кодов ASCII
 |
Обращаю ваше внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Для букв русского алфавита также соблюдается принцип последовательного кодирования.
Вторая половина таблицы кодов ASCII

К сожалению, в настоящее время существуют пять различных кодировок кириллицы (КОИ8-Р, Windows. MS-DOS, Macintosh и ISO). Из-за этого часто возникают проблемы с переносом русского текста с одного компьютера на другой, из одной программной системы в другую.
Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 ("Код обмена информацией, 8-битный"). Эта кодировка применялась еще в 70-ые годы на компьютерах серии ЕС ЭВМ, а с середины 80-х стала использоваться в первых русифицированных версиях операционной системы UNIX.
От начала 90-х годов, времени господства операционной системы MS DOS, остается кодировка CP866 ("CP" означает "Code Page", "кодовая страница").
Компьютеры фирмы Apple, работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac.
Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.
Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251.
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode . Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Попробуем с помощью таблицы ASCII представить, как будут выглядеть слова в памяти компьютера.
Внутреннее представление слов в памяти компьютера
Иногда бывает так, что текст, состоящий из букв русского алфавита, полученный с другого компьютера, невозможно прочитать - на экране монитора видна какая-то "абракадабра". Это происходит оттого, что на компьютерах применяется разная кодировка символов русского языка.
Все символы и буквы могут быть закодированы при помощи восьми двоичных бит. Наиболее распространенными таблицами представления букв в двоичном коде являются ASCII и ANSI, их можно использовать для записи текстов в микропроцессорах. В таблицах ASCII и ANSI первые 128 символов совпадают. В этой части таблицы содержатся коды цифр, знаков препинания, латинские буквы верхнего и нижнего регистров и управляющие символы. Национальные расширения символьных таблиц и символы псевдографики содержатся в последних 128 кодах этих таблиц, поэтому русские тексты в операционных системах DOS и WINDOWS не совпадают.
При первом знакомстве с компьютерами и микропроцессорами может возникнуть вопрос — "как преобразовать текст в двоичный код?" Однако это преобразование является наиболее простым действием! Для этого нужно воспользоваться любым текстовым редактором. В том числе подойдет и простейшая программа notepad, входящая в состав операционной системы Windows. Подобные же редакторы присутствуют во всех средах программирования для языков, таких как СИ, Паскаль или Ява. Следует отметить, что наиболее распространенный текстовый редактор Word для простого преобразования текста в двоичный код не подходит. Этот тестовый редактор вводит огромное количество дополнительной информации, такой как цвет букв, наклон, подчеркивание, язык, на котором написана конкретная фраза, шрифт.
Следует отметить, что на самом деле комбинация нулей и единиц, при помощи которых кодируется текстовая информация двоичным кодом не является, т.к. биты в этом коде не подчиняются законам . Однако в Интернете поисковая фраза "представление букв в двоичном коде" является самой распространенной. В таблице 1 приведено соответствие двоичных кодов буквам латинского алфавита. Для краткости записи в этой таблице последовательность нулей и единиц представлена в десятичном и шестнадцатеричном кодах.
Таблица 1 Таблица представления латинских букв в двоичном коде (ASCII)
| Десятичный код | Шестнадцатеричный код | Отображаемый символ | Значение |
|---|---|---|---|
| 0 | 00 | NUL | |
| 1 | 01 | ☺ | (слово управления дисплеем) |
| 2 | 02 | ☻ | (Первое передаваемое слово) |
| 3 | 03 | ETX (Последнее слово передачи) | |
| 4 | 04 | ♦ | EOT (конец передачи) |
| 5 | 05 | ♣ | ENQ (инициализация) |
| 6 | 06 | ♠ | ACK (подтверждение приема) |
| 7 | 07 | BEL | |
| 8 | 08 | ◘ | BS |
| 9 | 09 | ○ | HT (горизонтальная табуляция |
| 10 | 0A | ◙ | LF (перевод строки) |
| 11 | 0B | ♂ | VT (вертикальная табуляция) |
| 12 | 0С | ♀ | FF (следующая страница) |
| 13 | 0D | ♪ | CR (возврат каретки) |
| 14 | 0E | ♫ | SO (двойная ширина) |
| 15 | 0F | ☼ | SI (уплотненная печать) |
| 16 | 10 | DLE | |
| 17 | 11 | ◄ | DC1 |
| 18 | 12 | ↕ | DC2 (отмена уплотненной печати) |
| 19 | 13 | ‼ | DC3 (готовность) |
| 20 | 14 | ¶ | DC4 (отмена двойной ширины) |
| 21 | 15 | § | NAC (неподтверждение приема) |
| 22 | 16 | ▬ | SYN |
| 23 | 17 | ↨ | ETB |
| 24 | 18 | CAN | |
| 25 | 19 | ↓ | EM |
| 26 | 1A | → | SUB |
| 27 | 1B | ← | ESC (начало управл. послед.) |
| 28 | 1C | ∟ | FS |
| 29 | 1D | ↔ | GS |
| 30 | 1E | ▲ | RS |
| 31 | 1F | ▼ | US |
| 32 | 20 | Пробел | |
| 33 | 21 | ! | Восклицательный знак |
| 34 | 22 | « | Угловая скобка |
| 35 | 23 | # | Знак номера |
| 36 | 24 | $ | Знак денежной единицы (доллар) |
| 37 | 25 | % | Знак процента |
| 38 | 26 | & | Амперсанд |
| 39 | 27 | " | Апостроф |
| 40 | 28 | ( | Открывающая скобка |
| 41 | 29 | ) | Закрывающая скобка |
| 42 | 2A | * | Звездочка |
| 43 | 2B | + | Знак плюс |
| 44 | 2C | , | Запятая |
| 45 | 2D | - | Знак минус |
| 46 | 2E | . | Точка |
| 47 | 2F | / | Дробная черта |
| 48 | 30 | 0 | Цифра ноль |
| 49 | 31 | 1 | Цифра один |
| 50 | 32 | 2 | Цифра два |
| 51 | 33 | 3 | Цифра три |
| 52 | 34 | 4 | Цифра четыре |
| 53 | 35 | 5 | Цифра пять |
| 54 | 36 | 6 | Цифра шесть |
| 55 | 37 | 7 | Цифра семь |
| 56 | 38 | 8 | Цифра восемь |
| 57 | 39 | 9 | Цифра девять |
| 58 | 3A | : | Двоеточие |
| 59 | 3B | ; | Точка с запятой |
| 60 | 3C | < | Знак меньше |
| 61 | 3D | = | Знак равно |
| 62 | 3E | > | Знак больше |
| 63 | 3F | ? | Знак вопрос |
| 64 | 40 | @ | Коммерческое эт |
| 65 | 41 | A | Прописная латинская буква А |
| 66 | 42 | B | Прописная латинская буква B |
| 67 | 43 | C | Прописная латинская буква C |
| 68 | 44 | D | Прописная латинская буква D |
| 69 | 45 | E | Прописная латинская буква E |
| 70 | 46 | F | Прописная латинская буква F |
| 71 | 47 | G | Прописная латинская буква G |
| 72 | 48 | H | Прописная латинская буква H |
| 73 | 49 | I | Прописная латинская буква I |
| 74 | 4A | J | Прописная латинская буква J |
| 75 | 4B | K | Прописная латинская буква K |
| 76 | 4C | L | Прописная латинская буква L |
| 77 | 4D | M | Прописная латинская буква |
| 78 | 4E | N | Прописная латинская буква N |
| 79 | 4F | O | Прописная латинская буква O |
| 80 | 50 | P | Прописная латинская буква P |
| 81 | 51 | Q | Прописная латинская буква |
| 82 | 52 | R | Прописная латинская буква R |
| 83 | 53 | S | Прописная латинская буква S |
| 84 | 54 | T | Прописная латинская буква T |
| 85 | 55 | U | Прописная латинская буква U |
| 86 | 56 | V | Прописная латинская буква V |
| 87 | 57 | W | Прописная латинская буква W |
| 88 | 58 | X | Прописная латинская буква X |
| 89 | 59 | Y | Прописная латинская буква Y |
| 90 | 5A | Z | Прописная латинская буква Z |
| 91 | 5B | [ | Открывающая квадратная скобка |
| 92 | 5C | \ | Обратная черта |
| 93 | 5D | ] | Закрывающая квадратная скобка |
| 94 | 5E | ^ | "Крышечка" |
| 95 | 5 | _ | Символ подчеркивания |
| 96 | 60 | ` | Апостроф |
| 97 | 61 | a | Строчная латинская буква a |
| 98 | 62 | b | Строчная латинская буква b |
| 99 | 63 | c | Строчная латинская буква c |
| 100 | 64 | d | Строчная латинская буква d |
| 101 | 65 | e | Строчная латинская буква e |
| 102 | 66 | f | Строчная латинская буква f |
| 103 | 67 | g | Строчная латинская буква g |
| 104 | 68 | h | Строчная латинская буква h |
| 105 | 69 | i | Строчная латинская буква i |
| 106 | 6A | j | Строчная латинская буква j |
| 107 | 6B | k | Строчная латинская буква k |
| 108 | 6C | l | Строчная латинская буква l |
| 109 | 6D | m | Строчная латинская буква m |
| 110 | 6E | n | Строчная латинская буква n |
| 111 | 6F | o | Строчная латинская буква o |
| 112 | 70 | p | Строчная латинская буква p |
| 113 | 71 | q | Строчная латинская буква q |
| 114 | 72 | r | Строчная латинская буква r |
| 115 | 73 | s | Строчная латинская буква s |
| 116 | 74 | t | Строчная латинская буква t |
| 117 | 75 | u | Строчная латинская буква u |
| 118 | 76 | v | Строчная латинская буква v |
| 119 | 77 | w | Строчная латинская буква w |
| 120 | 78 | x | Строчная латинская буква x |
| 121 | 79 | y | Строчная латинская буква y |
| 122 | 7A | z | Строчная латинская буква z |
| 123 | 7B | { | Открывающая фигурная скобка |
| 124 | 7С | | | Вертикальная черта |
| 125 | 7D | } | Закрывающая фигурная скобка |
| 126 | 7E | ~ | Тильда |
| 127 | 7F | ⌂ |
В классическом варианте таблицы символов ASCII нет русских букв и она состоит из 7 бит. Однако в дальнейшем эта таблица была расширена до 8 бит и в старших 128 строках появились русские буквы в двоичном коде и символы псевдографики. В общем случае во второй части размещены национальные алфавиты разных стран и русские буквы там просто один из возможных наборов (855) там может быть французская (863), немецкая (1141) или греческая (737) таблица. В таблице 2 приведен пример представления русских букв в двоичном коде.
Таблица 2. Таблица представления русских букв в двоичном коде (ASCII)
| Десятичный код | Шестнадцатеричный код | Отображаемый символ | Значение |
|---|---|---|---|
| 128 | 80 | А | Прописная русская буква А |
| 129 | 81 | Б | Прописная русская буква Б |
| 130 | 82 | В | Прописная русская буква В |
| 131 | 83 | Г | Прописная русская буква Г |
| 132 | 84 | Д | Прописная русская буква Д |
| 133 | 85 | Е | Прописная русская буква Е |
| 134 | 86 | Ж | Прописная русская буква Ж |
| 135 | 87 | З | Прописная русская буква З |
| 136 | 88 | И | Прописная русская буква И |
| 137 | 89 | Й | Прописная русская буква Й |
| 138 | 8A | К | Прописная русская буква К |
| 139 | 8B | Л | Прописная русская буква Л |
| 140 | 8C | М | Прописная русская буква М |
| 141 | 8D | Н | Прописная русская буква Н |
| 142 | 8E | О | Прописная русская буква О |
| 143 | 8F | П | Прописная русская буква П |
| 144 | 90 | Р | Прописная русская буква Р |
| 145 | 91 | С | Прописная русская буква С |
| 146 | 92 | Т | Прописная русская буква Т |
| 147 | 93 | У | Прописная русская буква У |
| 148 | 94 | Ф | Прописная русская буква Ф |
| 149 | 95 | Х | Прописная русская буква Х |
| 150 | 96 | Ц | Прописная русская буква Ц |
| 151 | 97 | Ч | Прописная русская буква Ч |
| 152 | 98 | Ш | Прописная русская буква Ш |
| 153 | 99 | Щ | Прописная русская буква Щ |
| 154 | 9A | Ъ | Прописная русская буква Ъ |
| 155 | 9B | Ы | Прописная русская буква Ы |
| 156 | 9C | Ь | Прописная русская буква Ь |
| 157 | 9D | Э | Прописная русская буква Э |
| 158 | 9E | Ю | Прописная русская буква Ю |
| 159 | 9F | Я | Прописная русская буква Я |
| 160 | A0 | а | Строчная русская буква а |
| 161 | A1 | б | Строчная русская буква б |
| 162 | A2 | в | Строчная русская буква в |
| 163 | A3 | г | Строчная русская буква г |
| 164 | A4 | д | Строчная русская буква д |
| 165 | A5 | е | Строчная русская буква е |
| 166 | A6 | ж | Строчная русская буква ж |
| 167 | A7 | з | Строчная русская буква з |
| 168 | A8 | и | Строчная русская буква и |
| 169 | A9 | й | Строчная русская буква й |
| 170 | AA | к | Строчная русская буква к |
| 171 | AB | л | Строчная русская буква л |
| 172 | AC | м | Строчная русская буква м |
| 173 | AD | н | Строчная русская буква н |
| 174 | AE | о | Строчная русская буква о |
| 175 | AF | п | Строчная русская буква п |
| 176 | B0 | ░ | |
| 177 | B1 | ▒ | |
| 178 | B2 | ▓ | |
| 179 | B3 | │ | Символ псевдографики |
| 180 | B4 | ┤ | Символ псевдографики |
| 181 | B5 | ╡ | Символ псевдографики |
| 182 | B6 | ╢ | Символ псевдографики |
| 183 | B7 | ╖ | Символ псевдографики |
| 184 | B8 | ╕ | Символ псевдографики |
| 185 | B9 | ╣ | Символ псевдографики |
| 186 | BA | ║ | Символ псевдографики |
| 187 | BB | ╗ | Символ псевдографики |
| 188 | BC | ╝ | Символ псевдографики |
| 189 | BD | ╜ | Символ псевдографики |
| 190 | BE | ╛ | Символ псевдографики |
| 191 | BF | ┐ | Символ псевдографики |
| 192 | C0 | └ | Символ псевдографики |
| 193 | C1 | ┴ | Символ псевдографики |
| 194 | C2 | ┬ | Символ псевдографики |
| 195 | C3 | ├ | Символ псевдографики |
| 196 | C4 | ─ | Символ псевдографики |
| 197 | C5 | ┼ | Символ псевдографики |
| 198 | C6 | ╞ | Символ псевдографики |
| 199 | C7 | ╟ | Символ псевдографики |
| 200 | C8 | ╚ | Символ псевдографики |
| 201 | C9 | ╔ | Символ псевдографики |
| 202 | CA | ╩ | Символ псевдографики |
| 203 | CB | ╦ | Символ псевдографики |
| 204 | CC | ╠ | Символ псевдографики |
| 205 | CD | ═ | Символ псевдографики |
| 206 | CE | ╬ | Символ псевдографики |
| 207 | CF | ╧ | Символ псевдографики |
| 208 | D0 | ╨ | Символ псевдографики |
| 209 | D1 | ╤ | Символ псевдографики |
| 210 | D2 | ╥ | Символ псевдографики |
| 211 | D3 | ╙ | Символ псевдографики |
| 212 | D4 | ╘ | Символ псевдографики |
| 213 | D5 | ╒ | Символ псевдографики |
| 214 | D6 | ╓ | Символ псевдографики |
| 215 | D7 | ╫ | Символ псевдографики |
| 216 | D8 | ╪ | Символ псевдографики |
| 217 | D9 | ┘ | Символ псевдографики |
| 218 | DA | ┌ | Символ псевдографики |
| 219 | DB | █ | |
| 220 | DC | ▄ | |
| 221 | DD | ▌ | |
| 222 | DE | ▐ | |
| 223 | DF | ▀ | |
| 224 | E0 | р | Строчная русская буква р |
| 225 | E1 | с | Строчная русская буква с |
| 226 | E2 | т | Строчная русская буква т |
| 227 | E3 | у | Строчная русская буква у |
| 228 | E4 | ф | Строчная русская буква ф |
| 229 | E5 | х | Строчная русская буква х |
| 230 | E6 | ц | Строчная русская буква ц |
| 231 | E7 | ч | Строчная русская буква ч |
| 232 | E8 | ш | Строчная русская буква ш |
| 233 | E9 | щ | Строчная русская буква щ |
| 234 | EA | ъ | Строчная русская буква ъ |
| 235 | EB | ы | Строчная русская буква ы |
| 236 | EC | ь | Строчная русская буква ь |
| 237 | ED | э | Строчная русская буква э |
| 238 | EE | ю | Строчная русская буква ю |
| 239 | EF | я | Строчная русская буква я |
| 240 | F0 | Ё | Прописная русская буква Ё |
| 241 | F1 | ё | Строчная русская буква ё |
| 242 | F2 | Є | |
| 243 | F3 | є | |
| 244 | F4 | Ї | |
| 245 | F5 | Ї | |
| 246 | F6 | Ў | |
| 247 | F7 | ў | |
| 248 | F8 | ° | Знак градуса |
| 249 | F9 | ∙ | Знак умножения (точка) |
| 250 | FA | · | |
| 251 | FB | √ | Радикал (взятие корня) |
| 252 | FC | № | Знак номера |
| 253 | FD | ¤ | Знак денежной единицы (рубль) |
| 254 | FE | ■ | |
| 255 | FF |
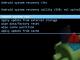
При записи текстов кроме двоичных кодов, непосредственно отображающих буквы, применяются коды, обозначающие переход на новую строку и возврат курсора (возврат каретки) на нулевую позицию строки. Эти символы обычно применяются вместе. Их двоичные коды соответствуют десятичным числам — 10 (0A) и 13 (0D). В качестве примера ниже приведен участок текста данной страницы (дамп памяти). На этом участке записан ее первый абзац. Для отображения информации в дампе памяти применен следующий формат:
- в первой колонке записан двоичный адрес первого байта строки
- в следующи шестнадцати колонках записаны байты, содержащиеся в текстовом файле. Для более удобного определения номера байта после восьмой колонки проведена вертикальная линия. Байты, для краткости записи, представлены в шестнадцатеричном коде.
- в последней колонке эти же байты представлены в виде отображаемых буквенных символов
В приведенном примере видно, что первая строка текста занимает 80 байт. Первый байт 82 соответствует букве "В". Второй байт E1 соответствует букве "с". Третий байт A5 соответствует букве "е". Следующий байт 20 отображает пустой промежуток между словами (пробел) " ". 81 и 82 байты содержат символы возврата каретки и перевода строки 0D 0A. Эти символы мы находим по двоичному адресу 00000050: Следующая строка исходного текста не кратна 16 (ее длина равна 76 буквам), поэтому для того, чтобы найти ее конец потребуется сначала найти строку 000000E0: и от нее отсчитать девять колонок. Там снова записаны байты возврата каретки и перевода строки 0D 0A. Остальной текст анализируется точно таким же образом.
Дата последнего обновления файла 04.12.2018
Литература:
Вместе со статьей "Запись текстов двоичным кодом" читают:
Представление двоичных чисел в памяти компьютера или
микроконтроллера
http://сайт/proc/IntCod.php
Иногда бывает удобно хранить числа в памяти процессора в десятичном
виде
http://сайт/proc/DecCod.php
Стандартные форматы чисел
с плавающей запятой для компьютеров и микроконтроллеров
http://сайт/proc/float/
В настоящее время и в технике и в быту широко используются как
позиционные, так и непозиционные системы счисления.
.php