Текстовая информация. Текстовая информация Текст как форма представления информации Текстовые документы Компьютер – основной инструмент подготовки текстов Ввод текста Редактирование
Каждой букве присваивается числовой номер. Например - букве «А» число 1, а букве «Б» - 2. Надо сказать, что прописные и заглавные буквы имеют разное число. В том числе, русский алфавит и латинский имеют свою кодировку. Для того чтобы различные компьютеры понимали друг - друга ученые выработали единый стандарт представления букв числами и назвали его «Кодировкой символов» «КОИ» (Рис. 1.1 .1).
Рис.1.1.1. Кодировка символов
Превратив буквы в числа, компьютер превращает числа в сигналы, и записывает их битами, из которых собираются байты:
А - 192- 11000000
Б - 193 - 11000001
В - 194- 11000010
Г- 195- 11000011
Графическая информация
Компьютеры могут работать с графической информацией. Это могут быть рисунки или фотографии. Для того чтобы картинка могла храниться и обрабатываться в компьютере, ей превращают в сигналы. Такое превращение называют оцифровкой (Рис. 1.1 .2).
Для оцифровки графической информации служат специальные цифровые фотокамеры или специальные устройства – сканеры.

Рис.1.1.2 Пример оцифровки рисунка
Цифровая камера работает, как обычный фотоаппарат, только изображение не попадает на фотопленку, а «запоминается» в электронной памяти такого «фотоаппарата». Потом такой аппарат подключают к компьютеру и по проводу передают сигналы, которыми зашифровано изображение.
Если картинка сделана на бумаге, то для того, чтобы превратить её в сигналы, используют сканеры. Картинку кладут в сканер. Сканер просматривает каждую точку этой картинки и передает в компьютер числа (байты), которыми зашифрован цвет каждой точки. Например:
Черная точка: 0, 0, 0;
Белая точка: 255, 255, 255;
Коричневая точка:153, 102, 51;
Светло-серая точка: 160, 160, 160;
Темно-серая точка: 80, 80, 80.
У каждого цвета свой шифр (его называют цветовым кодом).
Если каждый цвет передавать тремя байтами, то можно зашифровать более 16 миллионов цветов. Это гораздо больше, чем может различить человеческий глаз, но для компьютера это не предел.
Звуковая информация
Звук, музыка и человеческая речь поступает в компьютер в виде сигналов и тоже оцифровывается (Рис. 1.1 .3. Рис. 1.1 .4.), то есть превращается в числа, а потом - в байты и биты. Компьютер их хранит, обрабатывает и может воспроизвести (проиграть музыку или произнести слово).

Для того чтобы ввести звуковую информацию в компьютер, к нему подключают микрофон или соединяют с другими электронными музыкальными устройствами, например, с магнитофоном или проигрывателем. Если в компьютере есть специальная, звуковая плата, то он может обрабатывать звуковую информации и воспроизводить человеческую речь, музыку и звуки.

Видеоинформация
Современные компьютеры могут работать с видеоинформацией. Они могут записывать и воспроизводить видеофильмы, мультфильмы и кинофильмы. Как и все прочие виды информации, видеоинформация тоже превращается в сигналы и записывается в виде битов и байтов. Происходит это точно так же, как и с картинками - разница лишь в том, что таких «картинок» надо обрабатывать очень много.
Фильмы состоят из кадров. Каждый кадр - эго как бы отдельная картинка. Чтобы изображение на экране, выглядело «живой» и двигалось, кадры должны сменять друг друга с большой скоростью - 25 кадров в секунду. Если компьютер мощный и быстрый, то он может 25 раз в секунду обрабатывать в своей памяти новую картинку и показывать её на экране.
Сигналы для записи видеоизображений компьютер получает от видеокамеры. Как и все другие виды информации, он преобразует эти сигналы в биты и байты и записывает их в свою память.
Выводится видеоизображение на экран компьютерного монитора. При этом вместе с изображением может выводиться и звук.
Нажатие любой алфавитно-цифровой клавиши на клавиатуре приводит к тому, что в компьютер посылается сигнал в виде двоичного числа, представляющего собой одно из значений кодовой таблицы.
Кодовая таблица - это внутреннее представление символов в компьютере.
В качестве стандарта долгое время использовалась таблица \(ASCII \)(\(A\)merican \(S\)tandard \(C\)ode for \(I\)nformational \(I\)nterchange - Американский стандартный код информационного обмена ).
Для хранения двоичного кода одного символа выделен \(1\) байт \(=\) \(8 \)бит. Учитывая, что каждый бит принимает значение \(1\) или \(0\), количество возможных сочетаний единиц и нулей равно 2 8 = 256 .
Значит, с помощью \(1\) байта можно получить \(256\) разных двоичных кодовых комбинаций и отобразить с их помощью \(256\) различных символов.
Эти коды и составляют таблицу \(ASCII\).
Для сокращения записи и удобства пользования этими кодами символов в таблице используют шестнадцатеричную систему счисления, состоящую из \(16\) символов - \(10\) цифр и \(6\) латинских букв: \(A\), \(B\), \(C\), \(D\), \(E\), \(F\). При кодировании символов сначала записывается цифра столбца, а затем строки, на пересечении которых находится данный символ.
ASCII -коды
Например, латинская буква \(S\) в таблице \(ASCII\) представлена шестнадцатеричным кодом - \(53\). При нажатии клавиши с буквой \(S\) в память компьютера записывается код \(01010011\), представляющий собой двоичный эквивалент шестнадцатеричного числа \(53\). Этот код может быть получен путем замены каждой шестнадцатеричной цифры её двоичным представлением. В данном случае цифра \(5\) заменена кодом \(0101\), а цифра 3 - кодом \(0011\). При выводе буквы \(S\) на экран, компьютер выполняет декодирование: на основании этого двоичного кода строится изображение символа.
Обрати внимание!
Любой символ в таблице \(ASCII\) кодируется с помощью \(8\) двоичных разрядов или \(2\) шестнадцатеричных разрядов.
Стандарт \(ASCII\) кодирует первые \(128 \)символов от \(0\) до \(127\): цифры, буквы латинского алфавита, управляющие символы. Таблица выше отображает кодировку символов в шестнадцатеричной системе счисления.
Первые \(32\) символа являются управляющими и предназначены в основном для передачи команд управления. Их назначение может варьироваться в зависимости от программных и аппаратных средств. Вторая половина кодовой таблицы (от \(128\) до \(255\)) американским стандартом не определена и предназначена для символов национальных алфавитов, псевдографических и некоторых математических символов. В разных странах могут использоваться различные варианты второй половины кодовой таблицы.
Для сравнения рассмотрим число \(45\) для двух вариантов кодирования.
При использовании в тексте это число потребует для своего представления \(2\) байта, поскольку каждая цифра будет представлена своим кодом в соответствии с таблицей \(ASCII\). В шестнадцатеричной системе код будет выглядеть как \(3435\), в двоичной системе - \(00110100 00110101\).
При использовании в вычислениях код этого числа будет получен по специальным правилам перевода и представлен в виде \(8\)-разрядного двоичного числа \(00101101\), на что потребуется \(1\) байт.
В настоящее время широко распространен код \(Unicode\) . Эта кодировка поддерживается в большинстве операционных систем, во всех современных браузерах и многих программах.
Стандарт \(Unicode\) явился результатом сотрудничества Международной организации по стандартизации (\(ISO\)) с ведущими производителями компьютеров и программного обеспечения. В мире существует \(6700\) живых языков, но только \(50\) из них являются официальными языками государств. Письменностей используется около \(25\), что делает возможным создание универсального стандарта.
Для кодирования этих письменностей достаточно \(16\)-битового диапазона (\(2\) байта на символ), то есть диапазона от \(0000\) до \(FFFF\). Стандарт \(ASCII\) занимает в кодовом пространстве свое почетное место в диапазоне от \(0000\) до \(00FF\).
Каждой письменности выделен свой блок кодов. На сегодняшний день кодирование всех живых официальных письменностей считается завершенным: распределено около \(29000\) позиций из \(65535\) возможных.
Кодовая таблица Unicode
В последнее время консорциум \(Unicode\) приступил к кодированию остальных письменностей нашей планеты, которые представляют какой-либо интерес: письменности мёртвых языков, выпавших из современного обихода, китайские иероглифы, искусственно созданные алфавиты и т. п.
Для представления такого разнообразия языков \(16\)-битового кодирования уже недостаточно, и сегодня \(Unicode\) уже приступил к освоению \(21\)-битового пространства кодов (\(000000\)-\(10FFFF\)), которое разбито на \(16\) зон, названных плоскостями.
- текст
- текстовый документ
- текстовый редактор
- правила ввода текста
- редактирование
- форматирование
- Ключевые слова:
Текст как форма представления информации
Всякий письменный текст - это определённая последовательность символов. Пропуск, замена или перестановка хотя бы одного символа в тексте подчас изменяет его смысл. Рассмотрим две фразы, отличающиеся одна от другой единственным, последним символом:
Кто к нам пришёл!
Кто к нам пришёл?
Смысл первой последовательности символов состоит в том, что вошедшего увидели и узнали. Вторая последовательность символов является вопросом, подчеркивающим неизвестность и неопредел ённость ситуации.
На протяжении тысячелетий люди записывали информацию. В течение этого времени менялось и то, на чём записывали информацию (камень, глина, дерево, папирус, пергамент, бумага), и то, с помощью чего это делали (острый камень, костяная палочка, птичье перо, перьевые ручки, авторучки, с конца XIX века для выполнения письменных работ стала применяться пишущая машинка). Но не менялось главное: чтобы внести изменения в текст, его надо было заново переписать. А это очень длительный и трудоёмкий процесс.
Появление компьютеров коренным образом изменило технологию письма. С помощью специальных компьютерных программ можно набрать любой текст, при необходимости внести в него изменения, записать текст в память компьютера для длительного хранения, отпечатать на принтере какое угодно количество копий текста без его повторного ввода или отправить текст с помощью электронной почты на другие компьютеры.
Дополнительную информацию об истории создания текстовых документов вы найдёте в электронном приложении к учебнику.
Текстовые документы
Текстовый документ может быть статьёй, докладом, рассказом, стихотворением, приглашением, объявлением, поздравительной открыткой. При работе в сети части одного сложного документа могут храниться на разных компьютерах, расположенных далеко друг от друга.
Гипертекст - это способ организации документа, позволяющий быстро находить нужную информацию. Он часто используется при построении систем оперативной подсказки и компьютерных версий больших справочников и энциклопедий. Переход с одного места в гипертексте на другое осуществляется с помощью ссылок. Например, пусть вы читаете энциклопедию о животных, и вас особенно интересует информация о собаках. Предположим, что слово «бульдог» подчёркнуто - это обозначает ссылку внутри гипертекста. Если вы щёлкнете на этом слове мышью, то попадёте в другую статью энциклопедии, которая рассказывает про эту породу собак.
Основными объектами текстового документа являются: символ, слово, строка, абзац, страница, фрагмент.
Символ - цифра, буква, знак препинания и т. д.
Слово - произвольная последовательность символов (букв, цифр и др.), ограниченная с двух сторон служебными символами (такими как пробел, запятая, скобки и др.).
Строка - произвольная последовательность символов между левой и правой границами документа.
Абзац - произвольная последовательность символов, ограниченная специальными символами конца абзаца. Допускаются пустые абзацы.
Фрагмент - произвольная последовательность символов. Фрагментом может быть отдельное слово, строка, абзац, страница и даже весь вводимый текст.
Компьютер - основной инструмент подготовки текстов
Подготовка текстов - одна из самых распространённых сфер применения компьютеров. На любом компьютере установлены специальные программы, предназначенные для создания текстов, - текстовые редакторы.
Вы уже работали с простым текстовым редактором. С его помощью можно создавать простые тексты, состоящие из букв, цифр, знаков препинания и специальных символов, которые можно ввести с помощью клавиатуры.
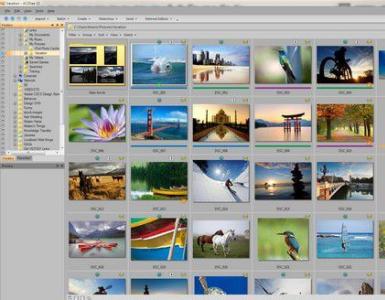
Для создания и оформления рассказов, докладов, статей для школьной газеты, содержащих надписи, таблицы, схемы, рисунки, фотографии, используют более мощные текстовые редакторы. Их ещё называют текстовыми процессорами.
Окно одного из простых текстовых процессоров показано на рис. 24.
Рис. 24
Подготовка документа на компьютере состоит из таких этапов, как ввод (набор), редактирование, форматирование и печать.
Ввод текста
Ввод (набор) текста, как правило, осуществляется с помощью клавиатуры. Место для ввода очередного символа текста указывается на экране монитора с помощью мигающей вертикальной черты - курсора.
При вводе текста придерживайтесь следующих правил:
- Там, где это нужно, используйте прописные буквы.
- Все знаки препинания, кроме тире, ставьте сразу же за последней буквой слова; после любого знака препинания нажимайте клавишу Пробел. Тире выделяйте пробелами с двух сторон.
- Избегайте ввода подряд двух и более пробелов; не используйте пробел для выравнивания границ абзаца.
- Не следите за концом строки: как только он будет достигнут, курсор автоматически перейдёт на начало следующей строки.
- Для того чтобы перейти к вводу нового абзаца (или строки стихотворения), нажимайте клавишу Enter.
Контролировать соблюдение правил набора текста будет значительно проще, если установить режим отображения непечатаемых символов.
Редактирование текста
Редактирование - следующий этап подготовки документа на компьютере. При редактировании текста вы просматриваете его, чтобы убедиться, что всё правильно, исправляете обнаруженные ошибки (например, в правописании) и вносите необходимые изменения.
Если текст большой, то на экране будет видна только его часть, а весь он будет храниться в памяти компьютера.
С помощью курсорных стрелок курсор можно перемещать по всему экрану, подводить его к любому символу. Для перемещения по всему документу предназначены специальные клавиши или комбинации клавиш:

Кроме того, существует режим прокрутки, позволяющий быстро вывести на экран части текста, находящиеся за его пределами.
При редактировании можно работать не только с отдельными символами, но и с целыми фрагментами текста. Предварительно фрагмент должен быть выделен. Для этого необходимо установить указатель мыши в начало нужного фрагмента и, держа кнопку мыши нажатой, протянуть указатель до его конца.
Выбор фрагмента можно отменить щелчком в произвольном месте рабочей области окна.
Выделенный фрагмент можно удалить из текста и стереть из памяти, а можно удалить из текста, но поместить в специальный раздел памяти, называемый буфером. В этом случае удалённый фрагмент можно будет или вернуть на прежнее место, или поместить в другое, более подходящее место текста (рис. 25).

Рис. 25
Иногда приходится вводить тексты, в которых отдельные строки, а то и группы строк неоднократно повторяются (вспомните стихотворение С. Маршака «Багаж» или какую-нибудь песенку с припевом). Повторяющийся фрагмент набирается только один раз, затем он выделяется и с помощью специальной кнопки копируется - сам фрагмент остаётся на своём прежнем месте, а его точная копия помещается в буфер. После этого вы продолжаете набирать текст и, дойдя до того места, где должен быть повторяющийся фрагмент, вставляете его из буфера. Эту процедуру можно повторять много раз.
Текстовые процессоры позволяют находить в тексте заданное слово, при необходимости автоматически заменять во всём тексте одно слово другим.
Современным текстовым процессорам можно поручить также обнаружение и исправление орфографических ошибок.
Форматирование текста
На этапе форматирования совершаются различные операции по оформлению документа.
Вначале абзацы текста выравниваются.
Когда текст выровнен влево, левая граница абзаца образует прямую линию. При этом все строки имеют одинаковые отступы от края страницы. Данный абзац выровнен влево.
Когда текст выровнен вправо, правая граница абзаца образует прямую линию. Каждая строка абзаца заканчивается на одном и том же расстоянии от края страницы. Данный абзац выровнен вправо.
Выровненный по центру, или центрированный, текст располагается так: с обеих сторон каждой строки ширина свободного пространства одинакова. С обеих сторон края абзаца получаются неровными. Данный абзац выровнен по центру.
Многие редакторы текстов «умеют» автоматически разбивать текст на страницы и нумеровать их. Они могут следить за размером полей и регулировать расстояние между строками, предлагают на выбор различные варианты шрифтов.
Шрифт - это полный набор букв алфавита с общим стилем их изображения.
Нормальный шрифт ничем не выделяется.
- Полужирный шрифт темнее, он хорошо заметен.
- Курсивный шрифт имеет наклон.
- Подчёркнутый шрифт.
Размер шрифта, или кегль, - это высота шрифта, измеряемая от нижнего края самой низкой буквы (например, «р» или «у») до верхнего края самой высокой буквы (например, «б»). Размер шрифта измеряется в пунктах. Один пункт - это очень маленькая единица, равная 1/72 дюйма 1 (0,3 мм), т. е. шрифт в 72 пункта имеет высоту 1 дюйм. В большинстве книг чаще всего используется шрифт размером 10-12 пунктов.
-
1 Дюйм - единица длины в английской системе мер, равна 2,54 см.
Дополнительную информацию о шрифтах вы найдёте в электронном приложении к учебнику.
Для вывода документа на бумагу к компьютеру подключается печатающее устройство - принтер. Существуют различные типы принтеров.
Матричный принтер печатает с помощью металлических иголок, которые прижимают к бумаге красящую ленту. Ударяя по ленте, они оставляют на бумаге узор из точек - матрицу буквы.
Струйный принтер наносит буквы на бумагу, распыляя над ней капли жидких чернил.
В лазерном принтере для печати символов используется лазерный луч. Это позволяет получать типографское качество печати.
Важная информация о создании текстовых документов на компьютере изложена в видеолекции «Приёмы работы с текстом», размещённой в Единой коллекции цифровых образовательных ресурсов (sc.edu.ru).
Самое главное
Текст - это любое словесное высказывание, напечатанное, написанное или существующее в устной форме.
Информация, представленная в форме письменного текста, называется текстовой информацией.
Для обработки текстовой информации предназначены специальные программы - текстовые редакторы.
Любой текст, созданный с помощью текстового редактора, вместе с включёнными в него нетекстовыми материалами называют документом.
Подготовка документа на компьютере состоит из таких этапов, как ввод (набор), редактирование и форматирование.
Вопросы и задания
- Расскажите о текстовой форме представления информации. Какие другие формы представления информации вы знаете? Расскажите о преимуществах или недостатках представления информации в виде текста по сравнению с описанной вами.
- С какой целью вы создаёте тексты? Приведите два-три примера.
- Приведите примеры текстов, различающихся по размеру, по оформлению, по назначению.
- Какие принципиальные изменения в процесс создания текста внёс компьютер?
- Как вы понимаете смысл высказывания: «Что написано пером, то не вырубить топором»? Согласны ли вы с этим?
- Что общее и в чём различие возможностей текстового процессора и текстового редактора?
- Что вы понимаете под текстовым документом?
- Перечислите основные этапы подготовки текстового документа на компьютере.
- Какие правила необходимо соблюдать при наборе (вводе) текста?
- Как можно преобразовать текст на этапе его редактирования?
- Какие способы «перемещения» по большому текстовому документу вам известны?
- Для чего необходимо осуществлять форматирование текста? Как можно преобразовать текст на этом этапе?
- Как называется устройство для вывода документа на бумагу?
- Какой способ создания текста - компьютерный или рукописный - вам нравится больше? Свой выбор обоснуйте.
- Одно из значений слова «редактор» - лицо, исправляющее рукопись с согласия автора. Попытайтесь на основе этой информации объяснить, почему компьютерные программы для создания текстов назвали текстовыми редакторами.
Компьютерный практикум
Работа 5 «Вводим текст»
Работа 6 «Редактируем текст»
Работа 7 «Работаем с фрагментами текста»
Работа 8 «Форматируем текст»
Урок: «Текстовая информация»
Текст как форма представления информации
Текст – это любое словесное высказывание напечатанное, написанное или существующее в устной форме.
Информация, представленная в форме письменного текста, называется текстовой информацией.
Удивительный факт! Пропуск, замена или перестановка хотя бы одного символа в тексте подчас изменяет его смысл:
Кто к нам пришёл! (смысл состоит в том, что вошедшего увидели и узнали)
Кто к нам пришёл? (является вопросом, подчеркивающим неизвестность и неопределенность ситуации).
На протяжении тысячелетий люди записывали информацию.
Носители информации: камень, глина, дерево, папирус, пергамент, бумага.
Но чтобы внести изменения в текст, его надо было заново переписать. А это очень длительный и трудоемкий процесс. Появление компьютеров изменило технологию письма. С помощью специальных компьютерных программ можно набрать любой текст, при необходимости внести в него изменения, записать текст в память компьютера для длительного хранения, напечатать на принтере какое угодно количество копий, отправить текст с помощью электронной почты на другие компьютеры.
Текстовые документы
Документ – любой текст, созданный с помощью текстового редактора, вместе с включёнными в него нетекстовыми материалами.
Текстовый документ может быть:
Гипертекст – это способ организации документа, позволяющий быстро находить нужную информацию . Переход с одного места в гипертексте на другое осуществляется с помощью ссылок.
Пример: вы читаете энциклопедию о животных, и вас особенно интересует информация о собаках. Пусть слово «овчарка» подчеркнуто – это обозначает ссылку внутри гипертекста. Если вы щёлкните на этом слове мышью, то попадете в другую статью энциклопедии, которая рассказывает про эту породу собак.
Основными объектами текстового документа являются: символ, слово, строка, абзац, страница, фрагмент.
Символ – цифра, буква, знак препинания и т.д.
Слово – произвольная последовательность символов, ограниченная с двух сторон служебными символами(пробел, скобки, запятая и др.).
Строка – произвольная последовательность символов между левой и правой границами документа.
Абзац – произвольная последовательность символов, ограниченная специальными символами конца абзаца.
Фрагмент – произвольная последовательность символов. Фрагментом может быть отдельное слово, строка, абзац, страница и даже весь вводимый текст.
Компьютер – основной инструмент подготовки текстов
На любом компьютере установлены специальные программы, предназначенные для создания текстов, - текстовые редакторы .
Для создания и оформления рассказов, докладов, статей для школьной газеты, содержащих надписи, таблицы, схемы, рисунки, фотографии, используют более мощные текстовые редакторы. Их еще называют текстовыми процессорами.
Окно одного из простых текстовых процессоров показано на рис. 24 стр.58.

Подготовка документа на компьютере состоит из нескольких этапов: ввод (набор) текста , редактирование , форматирование и печать.

Ввод текста
При вводе текста придерживайтесь следующих правил :
Там, где это нужно, используйте прописные буквы.
Все знаки препинания, кроме тире, ставьте сразу же за последней буквой слова; после любого знака препинания нажимайте клавишу Пробел. Тире выделяйте пробелами с двух сторон.
Избегайте ввода подряд двух и более пробелов; не используйте пробел для выравнивания границ абзаца.
Не следите за концом строки: как только он будет достигнут, курсор автоматически перейдёт на начало следующей строки.
Для перехода к вводу нового абзаца, нажмите клавишу Enter .
Контролировать соблюдение правил набора текста будет значительно проще, если установить режим отображения непечатаемых символов.
Редактирование текста
Редактирование – это очередной этап подготовки документа, начинающийся вслед за вводом информации, в результате которого происходит проверка документа на его правильность и исправляются обнаруженные ошибки, а так же вносятся необходимые изменения.
С помощью курсорных стрелок курсор можно перемещать по всему экрану, подводить его к любому символу. Для перемещения по всему документу предназначены специальные клавиши или комбинации клавиш(см. учебник стр. 59).
При редактировании можно работать не только с отдельными символами, но и с целыми фрагментами текста. Предварительно фрагмент должен быть выделен. Для этого необходимо установить указатель мыши в начало нужного фрагмента и, держа кнопку мыши нажатой, протянуть указатель до его конца. Текст выделяется контрастным цветом. Выбор фрагмента можно отменить щелчком в произвольном месте рабочей области окна.

Форматирование текста
Форматирование – это один из этапов подготовки документа, в ходе которого совершаются различные операции по оформлению документа.

Выравнивание абзацев:

Шрифт – это полный набор букв алфавита с общим стилем их изображения.
Начертание шрифта:


Для вывода документа на бумагу к компьютеру подключается печатающее устройство – принтер.

Юнико́д
- стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода». Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц.
Стандарт состоит из двух основных разделов: универсальный набор символов и семейство кодировок. Универсальный набор символов задаёт однозначное соответствие символов кодам - элементам кодового пространства, представляющим неотрицательные целые числа. Семейство кодировок определяет машинное представление последовательности кодов UCS.
Коды в стандарте Юникод разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F (см. Кириллица в Юникоде).
Система кодирования
Универсальная система кодирования (Юникод) представляет собой набор графических символов и способ их кодирования для компьютерной обработки текстовых данных.
Графические символы - это символы, имеющие видимое изображение. Графическим символам противопоставляются управляющие символы и символы форматирования. Графические символы включают в себя следующие группы: буквы, содержащиеся хотя бы в одном из обслуживаемых алфавитов; цифры; знаки пунктуации; специальные знаки (математические, технические, идеограммы и пр.); разделители.
Юникод - это система для линейного представления текста. Символы, имеющие дополнительные над- или подстрочные элементы, могут быть представлены в виде построенной по определённым правилам последовательности кодов (составной вариант, composite character) или в виде единого символа (монолитный вариант, precomposed character).
Модифицирующие символы
Графические символы в Юникоде подразделяются на протяжённые и непротяжённые (бесширинные). Непротяжённые символы при отображении не занимают места в строке. К ним относятся, в частности, знаки ударения и прочие диакритические знаки. Как протяжённые, так и непротяжённые символы имеют собственные коды. Протяжённые символы иначе называются базовыми, а непротяжённые - модифицирующими; причём последние не могут встречаться самостоятельно. Например, символ «á» может быть представлен как последовательность базового символа «a» (U+0061) и модифицирующего символа « ́» (U+0301) или как монолитный символ «á» (U+00C1).
Особый тип модифицирующих символов - селекторы варианта начертания. Они действуют только на те символы, для которых такие варианты определены. В версии 5.0 варианты начертания определены для ряда математических символов, для символов традиционного монгольского алфавита и для символов монгольского квадратного письма.
Формы нормализации
Поскольку одни и те же символы можно представить различными кодами, что иногда затрудняет обработку, существуют процессы нормализации, предназначенные для приведения текста к определённому стандартному виду.
В стандарте Юникода определены 4 формы нормализации текста:
Форма нормализации D (NFD) - каноническая декомпозиция. В процессе приведения текста в эту форму все составные символы рекурсивно заменяются на несколько составных, в соответствии с таблицами декомпозиции.
Форма нормализации C (NFC) - каноническая декомпозиция с последующей канонической композицией. Сначала текст приводится к форме D, после чего выполняется каноническая композиция - текст обрабатывается от начала к концу и выполняются следующие правила:
Символ S является начальным, если он имеет нулевой класс модификации в базе символов Юникода.
В любой последовательности символов, стартующей с начального символа S, символ C блокируется от S, если и только если между S и C есть какой-либо символ B, который или является начальным, или имеет одинаковый или больший класс модификации, чем C. Это правило распространяется только на строки, прошедшие каноническую декомпозицию.
Первичным композитом считается символ, у которого есть каноническая декомпозиция в базе символов Юникода (или каноническая декомпозиция для хангыля и он не входит всписок исключений).
Символ X может быть первично совмещён с символом Y, если и только если существует первичный композит Z, канонически эквивалентный последовательности
Если очередной символ C не блокируется последним встреченным начальным базовым символом L и он может быть успешно первично совмещён с ним, то L заменяется на композит L-C, а C удаляется.
Форма нормализации KD (NFKD) - совместимая декомпозиция. При приведении в эту форму все составные символы заменяются, используя как канонические карты декомпозиции Юникода, так и совместимые карты декомпозиции, после чего результат ставится в каноническом порядке.
Форма нормализации KC (NFKC) - совместимая декомпозиция с последующей канонической композицией.
Термины «композиция» и «декомпозиция» понимают под собой соответственно соединение или разложение символов на составные части.
Примеры
| Исходный текст | NFD | NFC | NFKD | NFKC |
|---|---|---|---|---|
| Français | Franc\u0327ais | Fran\xe7ais | Franc\u0327ais | Fran\xe7ais |
| А, Ё, Й | \u0410, \u0401, \u0419 | \u0410, \u0415\u0308, \u0418\u0306 | \u0410, \u0401, \u0419 | |
| が | \u304b\u3099 | \u304c | \u304b\u3099 | \u304c |
| Henry IV | Henry IV | Henry IV | Henry IV | Henry IV |
| Henry Ⅳ | Henry \u2163 | Henry \u2163 | Henry IV | Henry IV |
Юникод
включает практически все современные письменности, в том числе:
арабскую, армянскую, бенгальскую, бирманскую, глаголицу, греческую, грузинскую, деванагари, еврейскую, кириллицу, китайскую (китайские иероглифы активно используются в японском языке, а также достаточно редко в корейском), коптскую, кхмерскую, латинскую, тамильскую, корейскую (хангыль), чероки, эфиопскую, японскую (которая включает в себя кроме китайских иероглифов ещё и слоговую азбуку),
и другие.
С академическими целями добавлены многие исторические письменности, в том числе: руны, древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
Способы представления
Юникод имеет несколько форм представления: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт. 1 апреля 2005 годабыли предложены две шуточные формы представления: UTF-9 и UTF-18 (RFC 4042).
В Microsoft Windows NT и основанных на ней системах Windows 2000 и Windows XP в основном используется форма UTF-16LE. В UNIX-подобных операционных системах GNU/Linux,BSD и Mac OS X принята форма UTF-8 для файлов и UTF-32 или UTF-8 для обработки символов в оперативной памяти.
UTF-8
UTF-8 - представление Юникода, обеспечивающее наилучшую совместимость со старыми системами, использовавшими 8-битные символы. Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. И наоборот, в тексте UTF-8 любой байт со значением меньше 128 изображает символ ASCII с тем же кодом. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт (на деле, только до 4 байт, поскольку в Юникоде нет символов с кодом больше 10FFFF, и вводить их в будущем не планируется), в которых
первый байт всегда имеет вид 11xxxxxx, а остальные - 10xxxxxx.
Формат UTF-8 был изобретён 2 сентября 1992 года Кеном Томпсоном и Робом Пайком и реализован в Plan 9. Сейчас стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D.
Символы UTF-8 получаются из Unicode следующим образом:
В потоке данных UTF-16 старший байт может записываться либо перед младшим, либо после младшего. Аналогично существует два варианта четырёхбайтной кодировки - UTF-32BE и UTF-32LE.
Для определения формата представления Юникода в начало текстового файла записывается сигнатура - символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемыйметкой порядка байтов (англ. byte order mark, BOM). Это позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует. Также этот способ иногда применяется для обозначения формата UTF-8, хотя к этому формату и неприменимо понятие порядка байтов. Файлы, следующие этому соглашению, начинаются с таких последовательностей байтов:UTF-8 EF BB BFUTF-16BE FE FFUTF-16LE FF FEUTF-32BE 00 00 FE FFUTF-32LE FF FE 00 00
К сожалению, этот способ не позволяет надёжно различать UTF-16LE и UTF-32LE, поскольку символ U+0000 допускается Юникодом (хотя реальные тексты редко начинаются с него).
Файлы в кодировках UTF-16 и UTF-32, не содержащие BOM, должны иметь порядок байтов big-endian (unicode.org).
Юникод и традиционные кодировки
Внедрение Юникода привело к изменению подхода к традиционным 8-битным кодировкам. Если раньше кодировка задавалась шрифтом, то теперь она задаётся таблицей соответствия между данной кодировкой и Юникодом. Фактически 8-битные кодировки превратились в форму представления некоторого подмножества Юникода. Это намного упростило создание программ, которые должны работать с множеством разных кодировок: теперь, чтобы добавить поддержку ещё одной кодировки, надо всего лишь добавить ещё одну таблицу перекодировки в Юникод.
Кроме того, многие форматы данных позволяют вставлять любые символы Юникода, даже если документ записан в старой 8-битной кодировке. Например, в HTML можно использоватькоды с амперсандом.
Реализации
Большинство современных операционных систем в той или иной степени обеспечивают поддержку Юникода.
В операционных системах семейства Windows NT для внутреннего представления имён файлов и других системных строк используется двухбайтовая кодировка UTF-16LE. Системные вызовы, принимающие строковые параметры, существуют в однобайтном и двухбайтном вариантах. Подробнее см. в статье Юникод в операционных системах Microsoft.
UNIX-подобные операционные системы, в том числе GNU/Linux, BSD, Mac OS X, используют для представления Юникода кодировку UTF-8. Большинство программ могут работать с UTF-8 как с традиционными однобайтными кодировками, не обращая внимания на то, что символ представляется как несколько последовательных байт. Для работы с отдельными символами строки обычно перекодируются в UCS-4, так что каждому символу соответствует машинное слово.
Одной из первых успешных коммерческих реализаций Юникода стала среда программирования Java. В ней принципиально отказались от 8-битного представления символов в пользу 16-битного. Сейчас большинство языков программирования поддерживают строки Юникода, хотя их представление может различаться в зависимости от реализации.
Методы ввода
Поскольку ни одна раскладка клавиатуры не может позволить вводить все символы Юникода одновременно, от операционных систем и прикладных программ требуется поддержка альтернативных методов ввода произвольных символов Юникода.
Microsoft Windows
Начиная с Windows 2000, служебная программа «Таблица символов» (charmap.exe) показывает все символы в ОС и позволяет копировать их в буфер обмена. Похожая таблица есть, например, в Microsoft Word.
Иногда можно набрать шестнадцатеричный код, нажать Alt+X, и код будет заменён на соответствующий символ, например, в WordPad, Microsoft Word. В редакторах Alt+X выполняет и обратное преобразование.
Во многих программах MS Windows, чтобы получить символ Unicode, нужно при нажатой клавише Alt набрать десятичное значение кода символа на цифровой клавиатуре. Например, полезными при наборе кириллических текстов будут комбинации Alt+0171 («) и Alt+0187 (»). Интересны также комбинации Alt+0133 (…) и Alt+0151 (-).
Macintosh
В Mac OS 8.5 и более поздних версиях поддерживается метод ввода, называемый «Unicode Hex Input». При зажатой клавише Option требуется набрать четырёхзначный шестнадцатеричный код требуемого символа. Этот метод позволяет вводить символы с кодами, большими U+FFFF, используя пары суррогатов; такие пары операционной системой будут автоматически заменены на одиночные символы. Этот метод ввода перед использованием нужно активизировать в соответствующем разделе системных настроек и затем выбрать как текущий метод ввода в меню клавиатуры.
Начиная с Mac OS X 10.2, существует также приложение «Character Palette», позволяющее выбирать символы из таблицы, в которой можно выделять символы определённого блока или символы, поддерживаемые конкретным шрифтом.
GNU/Linux
В GNOME также есть утилита «Таблица символов», позволяющая отображать символы определённого блока или системы письма и предоставляющая возможность поиска по названию или описанию символа. Когда код нужного символа известен, его можно ввести в соответствии со стандартом ISO 14755: при зажатых клавишах Ctrl и Shift ввести шестнадцатеричный код (начиная с некоторой версии GTK+ ввод кода нужно предварить нажатием клавиши «U»). Вводимый шестнадцатеричный код может иметь до 32 бит в длину, позволяя вводить любые символы Юникода без использования суррогатных пар.
Все приложения X Window, включая GNOME и KDE, поддерживают ввод при помощи клавиши Compose. Для клавиатур, на которых нет отдельной клавиши Compose, для этой цели можно назначить любую клавишу - например, Caps Lock.
Консоль GNU/Linux также допускает ввод символа Юникода по его коду - для этого десятичный код символа нужно ввести цифрами расширенного блока клавиатуры при зажатой клавише Alt. Можно вводить символы и по их шестнадцатеричному коду: для этого нужно зажать клавишу AltGr, и для ввода цифр A-F использовать клавиши расширенного блока клавиатуры от NumLock до Enter (по часовой стрелке). Поддерживается также и ввод в соответствии с ISO 14755. Для того чтобы перечисленные способы могли работать, нужно включить в консоли режим Юникода вызовом unicode_start(1) и выбрать подходящий шрифт вызовом setfont(8).
Mozilla Firefox для Linux поддерживает ввод символов по ISO 14755.